






什么是Data Pipeline?
今天我主要跟大家聊聊Data Pipeline在數(shù)據(jù)工作中的實際應用。在我們的日常工作中,無論是機器學習的建模,還是數(shù)據(jù)產(chǎn)品開發(fā),Data Pipeline實際上都是一個不可或缺的部分。特別是隨著數(shù)據(jù)來源更加多樣化、復雜化以及數(shù)據(jù)量的飛速增長,搭建一個高效的Data Pipeline,不僅能使你的工作事半功倍,更是很多復雜問題得以解決的關鍵所在。
我們先來看Data Pipeline的概念。從英文字面上看,Pipeline翻譯成中文,其實有兩層意思,它可以是管道、也可以是管道運輸?shù)囊馑肌Mㄋc兒來講,Data Pipeline可以理解為是一個貫穿了整個數(shù)據(jù)產(chǎn)品或者數(shù)據(jù)系統(tǒng)的一個管道,而數(shù)據(jù)就是這個管道所承載的主要對象。Data Pipeline連接了不同的數(shù)據(jù)處理分析的各個環(huán)節(jié),將整個龐雜的系統(tǒng)變得井然有序,便于管理和擴展。從而讓使用者能夠集中精力從數(shù)據(jù)中獲取所需要的信息,而不是把精力花費在管理日常數(shù)據(jù)和管理數(shù)據(jù)庫方面。
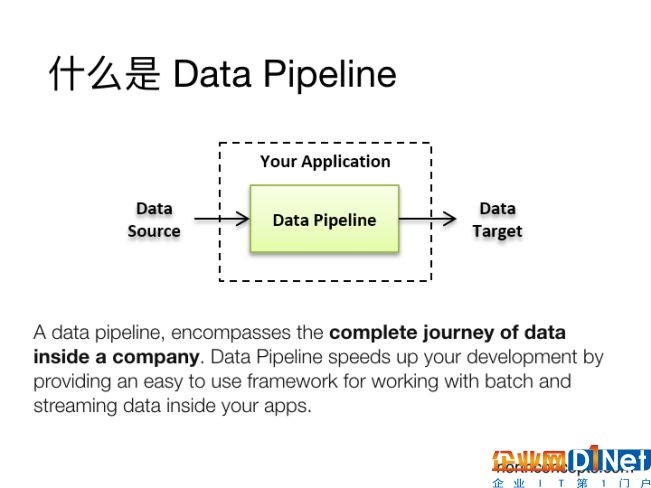
(圖片說明:Data Pipeline溝通了數(shù)據(jù)源和數(shù)據(jù)應用的目標,包含了一家公司內部的數(shù)據(jù)流動全過程)
在如今的實際數(shù)據(jù)工作中,我們需要處理的數(shù)據(jù)常常是多種多樣的。比如說設想這樣一個場景:如果我們需要對某一個產(chǎn)品進行一些分析,數(shù)據(jù)的來源可能是來自于社交媒體的用戶評論、點擊率,也有可能是從銷售渠道獲取的交易數(shù)據(jù)、或者歷史數(shù)據(jù),或者是從商品網(wǎng)站所抓取的產(chǎn)品信息。面對這么多不同的數(shù)據(jù)來源,你所要處理的數(shù)據(jù)可能包含CSV文件、也可能會有JSON文件、Excel等各種形式,可能是圖片文字,也可能是存儲在數(shù)據(jù)庫的表格,還有可能是來自網(wǎng)站、APP的實時數(shù)據(jù)。
在這種場景下,我們就迫切需要設計一套Data Pipeline來幫助我們對不同類型的數(shù)據(jù)進行自動化整合、轉換和管理,并在這個基礎上幫我們延展出更多的功能,比如可以自動生成報表,自動去進行客戶行為預測,甚至做一些更復雜的分析等。
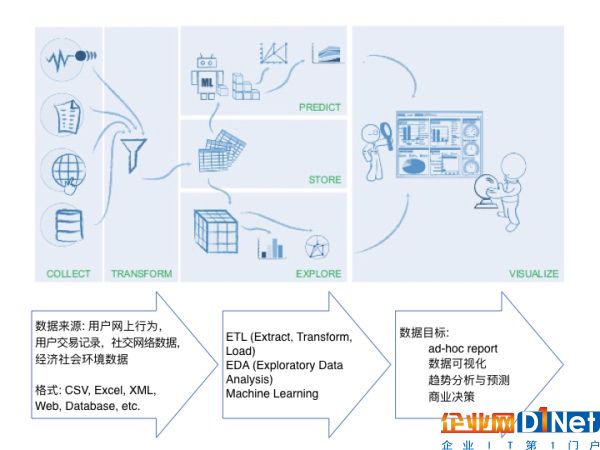
(圖片說明:從數(shù)據(jù)源到數(shù)據(jù)處理,再到實現(xiàn)數(shù)據(jù)目標的過程)
對于Data Pipeline,很多人習慣于將它和傳統(tǒng)的ETL(Extract-Transform-Load,指的是將數(shù)據(jù)從來源端經(jīng)過抽取、轉換、加載至目的端的過程)來對比。相對于傳統(tǒng)的ETL,Data Pipeline的出現(xiàn)和廣泛使用,主要是應對目前復雜的數(shù)據(jù)來源和應用需求,是跟“大數(shù)據(jù)”的需求密不可分的。
在實際應用中,目前Data Pipeline在機器學習、任務分析、網(wǎng)絡管理、產(chǎn)品研發(fā)方面都是被廣泛采用的。像是Facebook、Google或是國內的百度、騰訊這樣的數(shù)據(jù)驅動型的科技巨頭,它們的任何一個產(chǎn)品的開發(fā),都有一支龐大的數(shù)據(jù)工程師隊伍在后臺對整個產(chǎn)品的Data Pipeline進行設計開發(fā)和維護。
很多時候,我們甚至可以說,Data Pipeline的成敗是整個產(chǎn)品成敗的關鍵。
Data Pipeline在機器學習中的應用案例
Data Pipeline的應用有很多,我主要介紹一下其在機器學習中的應用。盡管在機器學習領域的應用只是Data Pipeline的一個小應用,但卻是非常成功的。
對于機器學習來說,Data Pipeline的主要任務就是讓機器對已有數(shù)據(jù)進行分析,從而能使機器對新的數(shù)據(jù)進行合理地判斷。
我想很多人都對Kaggle有所耳聞,可能也有一些人參與過Kaggle的項目。Kaggle是一個數(shù)據(jù)分析的平臺,企業(yè)或者研究者可以描述數(shù)據(jù)方面的問題,把對模型的期望發(fā)布到kaggle上面,以競賽的形式向廣大的數(shù)據(jù)科學愛好者征集更有效的解決方案。
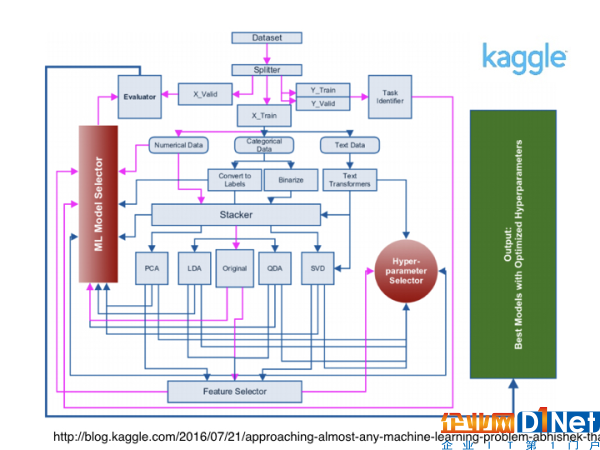
上面這張圖,是我從一位經(jīng)常參與Kaggle項目的達人的博客中拿到的。在和很多Kaggle達人的接觸中,其實我們可以發(fā)現(xiàn),他們大多數(shù)都會將Data Pipeline整合到自己的機器學習建模的流程中。
這張流程圖基本涵蓋了絕大多數(shù)機器學習要做的事情。如果你有一套合理的Data Pipeline來幫助你自動進行機器學習,那么其實可以省去大量的瑣碎的環(huán)節(jié),從而把精力集中在具體模型的分析上。
下面我們通過一個簡單的機器學習案例來看一下Data Pipeline是怎樣用于實際問題的。在這個案例中,我們用到的數(shù)據(jù)是來源于亞馬遜的產(chǎn)品分類信息,其中包含了產(chǎn)品介紹、用戶對產(chǎn)品的評分、評論,以及實時的數(shù)據(jù)。這個項目的主要目的是希望可以用這些實時獲取的數(shù)據(jù)構建模型,從而對新的產(chǎn)品進行打分。

在這個項目中,其實涉及了兩個Data Pipeline。第一個Data Pipeline是用于構建基本的模型。如下面這個流程圖。就是在機器學習過程中最基本的流程,包括了讀取數(shù)據(jù)、探索分析、模型選擇以及評估等。有了Data Pipeline,大大提升了運行效率。
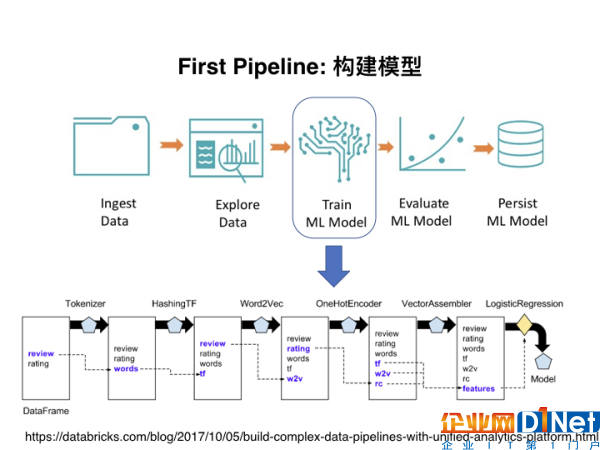
這樣一個類似模塊化設計的Data Pipeline,其應用到的很多組件在之前的代碼中就已經(jīng)設定好。如果我們在后續(xù)需要對Data Pipeline進行修改,只需要去修改最初的某個定義就可以。對于廣大碼農(nóng)來說,這可以說是節(jié)省了很多重復性的工作,而且使得代碼更加簡潔,查錯也更加方便。
有了最基本的模型,下一步就是構建第二個Data Pipeline,使其服務于實時預測。因為目前,數(shù)據(jù)是每分每秒都在更新,為了追求預測的準確性和時效性,大多數(shù)的公司都會對數(shù)據(jù)進行實時或是準實時的分析,從而就有了Data Pipeline的需求。
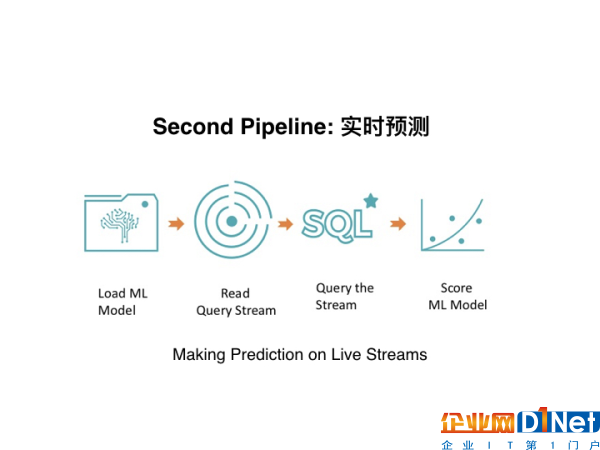
在第二個Data Pipeline中,最重要的兩個環(huán)節(jié)就是上圖中的read query stream(讀取實時數(shù)據(jù))、query the stream(實時計算數(shù)據(jù))這兩個環(huán)節(jié),它主要起到了實時去讀取數(shù)據(jù)、然后再對數(shù)據(jù)進行實時計算,給用戶一個實時的反饋的作用。這樣的話,數(shù)據(jù)就可以實現(xiàn)更大的價值。
第二個案例,則是一個更加具體的案例。很多朋友喜歡從Netflix上看美劇。作為一家成立于1997年,最初以出租DVD為主營業(yè)務,現(xiàn)在發(fā)展成為美國首屈一指的互聯(lián)網(wǎng)流媒體服務商,Netflix目前很大一部分業(yè)務其實都是基于數(shù)據(jù)處理和分析來完成的。

如果你通過APP或者是手機去使用Netflix服務,你很可能會遇到下面這樣的界面:
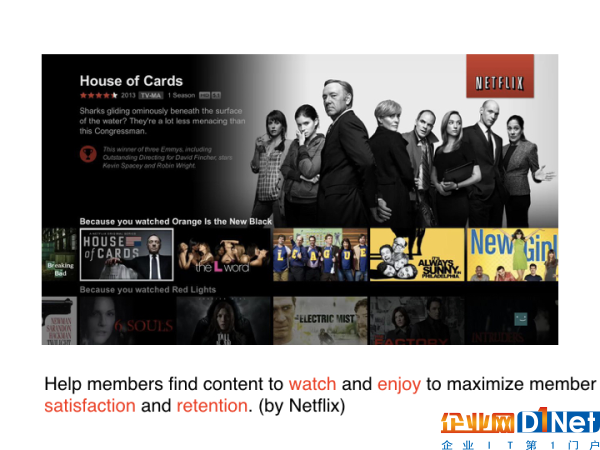
Netflix會根據(jù)你的瀏覽記錄來推斷你的喜好,從而給你進行個性化的推薦。憑借著這種實時而準確的用戶數(shù)據(jù)來推薦影片,Netflix吸引著更多的用戶去成為它的訂閱者。而事實上,它這種以數(shù)據(jù)為核心的商業(yè)模式,和它的規(guī)模也有很大關系。根據(jù)最新的統(tǒng)計結果,Netflix的用戶遍及了全球190個國家,每個月用戶的總活躍時間達到了30億個小時
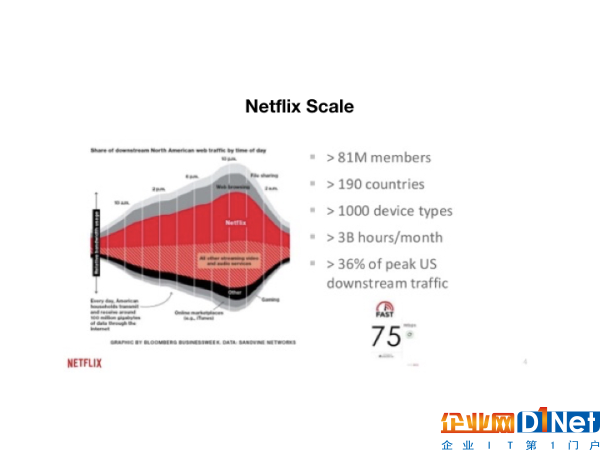
(圖片說明:Netflix的用戶規(guī)模和數(shù)據(jù)規(guī)模等)
有了這么豐富的數(shù)據(jù),是非常適合使用Data Pipeline的。Data Pipeline在Netflix的推薦系統(tǒng)中起到的作用是將來自全球的用戶數(shù)據(jù)進行整合分類,導入不同的時間、不同類型的模型中,從而對用戶的行為進行一個實時的預測。
Netflix的Data Pipeline系統(tǒng)可以分成三個部分:實時計算、準實時計算、離線部分。
實時計算部分,主要是用于對實時事件的響應和與用戶的互動,它必須在極短的時間里對用戶的請求作出響應,因此它比較適用于小量數(shù)據(jù)的簡單運算。而至于離線計算,它則不會受到這些因素的干擾,比較適用于大量數(shù)據(jù)的批處理運算。
準實時運算,則是介于實時和離線之間。它可以處理實時運算,但是又不要求很快給出結果。比如當用戶看過某部電影之后再給出推薦,就是準實時運算,可以用來對推薦系統(tǒng)進行更新,從而避免對用戶的重復推薦。
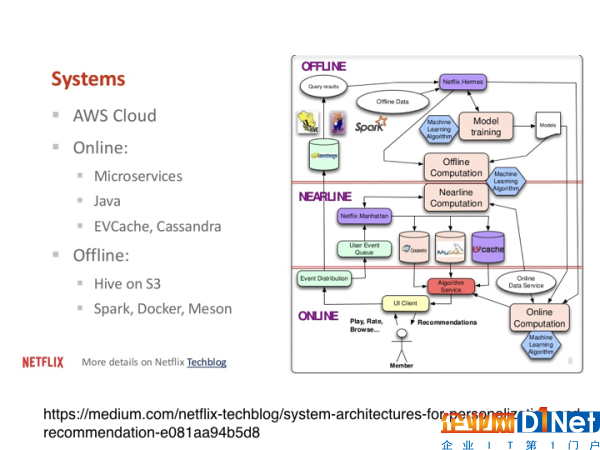
當然,Netflix要搭建Data Pipeline這樣的系統(tǒng),也有一定的技術和硬件要求。
比如,在下圖中你可以看到左邊列出了很多硬件上的要求。很多是在云端的服務,比如亞馬遜云服務(AWS)。在在線的運算系統(tǒng)中,如果對速度的要求很快,可能會用到Cassandra、EVCache。而對于離線的推薦和運算來說,我們需要的是對大數(shù)據(jù)的存儲,而不會太在乎它的速度快慢,所以這時候HIVE ON S3會是一個比較好的選擇。
搭建Data Pipeline的常見工具有哪些?
搭建Data Pipeline是一個復雜的數(shù)據(jù)工程,它牽扯很多因素,比如軟硬件協(xié)調,資金方面的投入等。這里我不再詳細說明。
下面,我想介紹一些常用的Data Pipeline相關工具。
首先是存儲方面,這個也是大家最容易接觸到的。首先,你需要知道你的數(shù)據(jù)從哪里來,它的速度、它的數(shù)據(jù)量是多少。然后你要知道當你的數(shù)據(jù)經(jīng)過數(shù)據(jù)處理之后,Data Pipeline需要把數(shù)據(jù)以什么樣的格式、存儲在怎樣一個數(shù)據(jù)環(huán)境里。
根據(jù)數(shù)據(jù)格式和數(shù)據(jù)數(shù)量的不同,你需要根據(jù)你的目的選擇合適的數(shù)據(jù)存儲方式。如果你的數(shù)據(jù)量特別大,你很有可能需要使用像是Hive這樣的基于大數(shù)據(jù)的數(shù)據(jù)存儲工具。
其次,你需要考慮到你要對數(shù)據(jù)進行怎樣的處理。比如,如果你需要做批量處理、實時分析等,這些問題都可能需要你使用能處理大量數(shù)據(jù)的工具。像是Spark就是比較流行的的處理方案,因為它包含了很多接口,基本上可以處理Data Pipeline中所需要面臨的絕大多數(shù)問題。
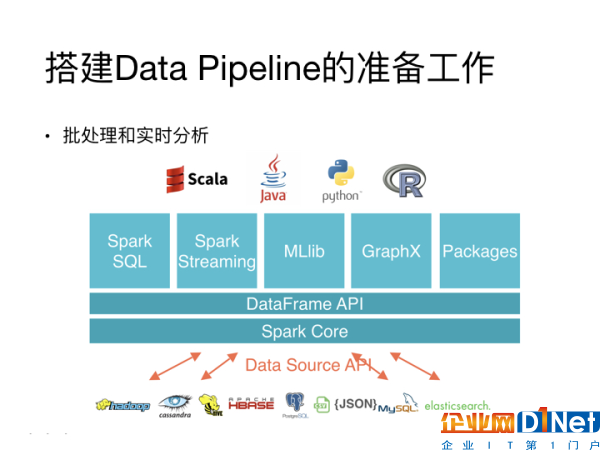
Data Pipeline相關的復雜工具有很多,你需要去認真選擇最適合的工具。
這里我想分享一個搭建Data Pipeline可能會用到的小管理工具。它是由Airbnb開發(fā)的一款叫做Airflow的小軟件。這個軟件是用Data Pipeline來寫的,對于Python的腳本有良好的支持。它的主要作用是對數(shù)據(jù)工作的調度提供可靠的流程,而且它還自帶UI,方便使用者監(jiān)督程序進程,進行實時的管理。

在Airflow這個軟件中,最重要的一個概念叫做DAG(有向無環(huán)圖)。關于DAG,前面提到的機器學習案例中其實已經(jīng)有了應用。在Airflow中,你可以將DAG看成是一個小的流程,這個小流程是由一個個有向的子任務組成,按照事先規(guī)定好的順序來一次順序執(zhí)行,最終達到Data Pipeline所要實現(xiàn)的目的。
由于時間關系,這里不再具體展開。簡而言之,我想說的是,在數(shù)據(jù)處理的過程中,Data Pipeline是一個很重要的系統(tǒng),而在搭建這樣的系統(tǒng)中,可以適當通過一些軟件來管理,從而獲得最好的效果。
















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號