






近期,字節(jié)跳動火山語音團隊的最新音樂檢索系統(tǒng) ByteCover2 入選了 ICASSP 2022。這一系統(tǒng)主要面向翻唱識別(CSI)這一音樂信息檢索(MIR)領(lǐng)域的一項重要任務(wù),通過表征學習方法讓其具備提取音樂核心特征的能力,并且該特征能夠?qū)ΨN類繁多的音樂重演繹具有良好的魯棒性,檢索速度提高 8 倍。經(jīng) Da-Tacos 數(shù)據(jù)集上的評估,準確率遠超其他方案的 SoTA 性能。
ByteCover2: 為高效翻唱識別系統(tǒng)設(shè)計的隱式嵌入降維方法
《BYTECOVER2: TOWARDS DIMENSIONALITY REDUCTION OF LATENT EMBEDDING FOR EFFICIENT COVER SONG IDENTIFICATION》
方法詳述:翻唱識別往往需要對音樂中的一些常見變化具有魯棒性,從而保證系統(tǒng)專注于對音樂旋律走向的建模。在設(shè)計翻唱識別系統(tǒng)時,有三種音樂變化通常會被重點考慮,即音樂調(diào)式偏移、音樂結(jié)構(gòu)變化和音樂節(jié)奏變化。此外,抖音平臺上每日新增千萬量級的用戶投稿,如何快速應對巨量查詢需求,提高識別系統(tǒng)的整體吞吐量并同時確保識別準確性,也是亟待解決的問題;另外在設(shè)計特征時,如何在保障其他性質(zhì)的前提下盡可能減小特征大小,從而減少存儲空間,降低系統(tǒng)復雜度和成本,也是字節(jié)跳動內(nèi)部開發(fā)翻唱識別時面臨的挑戰(zhàn)。
在 ByteCover 系統(tǒng)中,團隊通過多任務(wù)學習范式聯(lián)合 ResNet-IBN 模型,做到從音頻輸入中提取魯棒且具備區(qū)分性的向量表征。針對效率優(yōu)化問題,還提出了 PCA-FC 模塊,實踐證明該模塊在保證 ByteCover2 模型性能不變甚至提高的前提下可將向量尺寸壓縮至八分之一。

Bytecover 模型結(jié)構(gòu)與訓練流程
多任務(wù)學習提高音樂檢索能力:通常在翻唱識別領(lǐng)域存在兩種訓練范式,分別是多分類學習和度量學習。前者將每個曲目視為一個獨立類別,在特征層后加上全連接層,并通過交叉熵等分類損失對模型進行訓練,訓練完成后則去掉全連接層,使用特征層的輸出作為歌曲的表征;后者則直接在特征層之上,使用 triplet loss 等度量學習損失訓練網(wǎng)絡(luò)。
總體來看兩種訓練范式各有優(yōu)劣,團隊通過實驗發(fā)現(xiàn),分類損失往往能提高模型對同曲目不同風格版本的檢索能力,細致設(shè)計的度量學習損失則能提高翻唱網(wǎng)絡(luò)對相似風格不同曲目音樂的區(qū)分能力。因此 ByteCover 對這兩種學習范式進行了結(jié)合,并通過引入 BNNeck 模塊,提高了兩種損失的兼容性。
ResNet 網(wǎng)絡(luò)與 IBN 正則化方法(ResNet & Instance-Batch Normalization):為了簡化音樂特征提取的流程,加快特征提取速度,團隊使用 CQT 頻譜圖作為模型的輸入,而不使用在同期其他翻唱識別方法中常用的 cremaPCP 或其他更為復雜的特征,但此設(shè)計會天然地在輸入特征層面上損害模型對音頻頻移的魯棒性。
所以在選擇卷積神經(jīng)網(wǎng)絡(luò)做了音樂表征提取網(wǎng)絡(luò),希望能利用卷積網(wǎng)絡(luò)的平移不變性來實現(xiàn)模型對頻移的不變性。實驗證明,CQT 譜 + 普通 ResNet 的組合就已經(jīng)在效率和性能上超過 cremaPCP+CNN 的設(shè)計。
深入探究,團隊引入了 Instance-Batch Normalization 來從網(wǎng)絡(luò)隱表示的層面進一步學習和風格無關(guān)的音樂特征,即特征圖上不同通道間的均值方差等統(tǒng)計量與輸入的風格化特征相關(guān)。IN 通過對特征圖的通道維度做的歸一化處理,一定程度上實現(xiàn)了在隱藏表征層面上去除風格化信息,從而提高翻唱識別模型對音色變化的魯棒性。
特征降維模塊(PCA-FC):通過測算,團隊發(fā)現(xiàn)工業(yè)級別的翻唱系統(tǒng)大部分耗時集中在特征檢索階段,而這一階段的時間消耗基本和曲庫的大小以及特征向量的尺寸線性相關(guān)。曲庫中歌曲的數(shù)目會隨著業(yè)務(wù)的增長而不斷增加,因此降低特征向量尺寸成為優(yōu)化檢索系統(tǒng)整體耗時的必由之路,而同期其他翻唱向量特征降維的工作往往采用一個全連接層來將高維向量投影到維度更低的空間。
實驗結(jié)果發(fā)現(xiàn),單純使用全連接層進行降維會明顯降低系統(tǒng)的檢索能力,團隊認為這種現(xiàn)象不僅因為更小的尺寸限制了向量的表征能力,性能的損失也來自于隨機初始化的全連接層對特征各向同性的破壞。隨后對數(shù)據(jù)可視化之后我們可以發(fā)現(xiàn),降維后特征分布在一個錐形空間,表現(xiàn)出明顯的各向異性,此種性質(zhì)不利于使用余弦距離為度量的檢索。
因此團隊嘗試使用 PCA 對特征向量進行降維操作并隨后用 PCA 的變換矩陣初始化一個全連接層,把該層和特征提取網(wǎng)絡(luò)連接進來并聯(lián)合訓練,并將模塊稱作 PCA-FC。實驗結(jié)果顯示, PCA FC 能顯著提升降維模型的檢索性能,在保持檢索性能不變的前提下向量尺寸可以被壓縮八倍。
結(jié)果展示:一直以來 Da-Tacos 作為用來評估翻唱識別的基準測試數(shù)據(jù)集被使用,在該數(shù)據(jù)集上采用 1536 維的 ByteCover2 模型取得了遠超其他方案的 SoTA 性能,全類平均正確率指標 (mAP) 達到 79.1%;而 ByteCover 系列以外的最好方法 Re-MOVE 的該項指標只有 52.5%,更加值得被提及的一點,128 維的 ByteCover2 模型甚至超過了 2048 維的 ByteCover1 和 Re-MOVE 方法。

對比結(jié)果
此外,ByteCover1 系統(tǒng)還參加了 2020 國際音頻檢索評測大賽(MIREX),過程中大幅刷新了翻唱識別賽道歷年最好記錄,mAP 指標達到 84%,是同年參加該競賽的其他方案性能的 14 倍。
除了 ByteCover2,此次,字節(jié)跳動火山語音團隊還有多篇論文被 ICASSP 2022 收錄,內(nèi)容涵蓋智能音樂、音頻合成、音頻理解、超腦等多個方向,下面進行簡單介紹。
智能音樂
HTS-AT:一種用于聲音分類和檢測的分層標記語義音頻 Transformer 模型
《HTS-AT: A HIERARCHICAL TOKEN-SEMANTIC AUDIO TRANSFORMER FOR SOUND CLASSIFICATION AND DETECTION》
文章主要介紹了 HTS-AT,這是一種新穎的基于 Transformer 的聲音事件檢測模型。針對音頻任務(wù)的特性,該結(jié)構(gòu)能有效提高音頻頻譜信息在深度 Transformer 網(wǎng)絡(luò)中的流動效率,提高了模型對聲音事件的判別能力,并且通過降低輸出特征圖的大小,顯著降低了模型地計算量與內(nèi)存消耗。此外 HTS-AT 還引入了 Token Semantic 模塊,使模型具備預測聲音時間起始與終止點的能力,并且無需使用額外有標注數(shù)據(jù)進行訓練。
綜合以上技術(shù),HTS-AT 在標準數(shù)據(jù)集 AudioSet 上的 mAP 指標達到 0.471, 是當前的該數(shù)據(jù)集上的最佳水平,并且參數(shù)與計算量都小于之前的最佳方法;另外在聲音事件定位任務(wù)上,HTS-AT 無需額外標注數(shù)據(jù),即達到有監(jiān)督定位模型的性能水平。
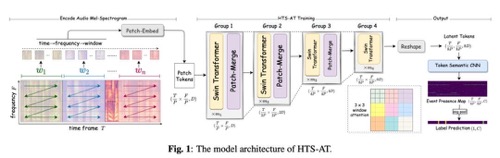
HTS-AT 模型的結(jié)構(gòu)
在音樂識別場景中,聲音事件檢測模型會挑選包含音樂的片段送入音樂檢索系統(tǒng),以此來提高整個系統(tǒng)的效率與準確性。
S3T: 針對音樂分類基于 Swin Transformer 的自監(jiān)督預訓練
《S3T: SELF-SUPERVISED PRE-TRAINING WITH SWIN TRANSFORMER FOR MUSIC CLASSIFICATION》
該篇文章提出了一種創(chuàng)新的、基于層級式 Transformer 的自監(jiān)督音樂預訓練算法 S3T。S3T 使用了大規(guī)模音樂預訓練配合少量標簽數(shù)據(jù)微調(diào)的范式,充分利用大量無標簽的音樂數(shù)據(jù),通過挖掘時域和頻域的信息,學習具有較強泛化性的通用音樂表征。S3T 在多個下游任務(wù)上均取得很好效果,特別是僅使用 10% 的標簽數(shù)據(jù)進行微調(diào)效果便能超過使用以往全量標簽數(shù)據(jù)訓練的模型,大幅降低了人工數(shù)據(jù)標注的成本。
S3T 模型結(jié)構(gòu)與訓練流程
音樂自監(jiān)督學習無需大量人工標簽便可利用大量音樂數(shù)據(jù)充分挖掘其自身的表征,且擁有較強的通用性。本文提出的音樂表征自監(jiān)督學習,為音樂理解構(gòu)筑了基礎(chǔ)。S3T 目前已經(jīng)應用在音樂標簽、音樂指紋等場景,微調(diào)后的 S3T 可以為音樂打上風格、語種、情緒等標簽,可靠的音樂標簽可以進一步服務(wù)音樂推薦系統(tǒng),使其精準地向來自不同地區(qū)的用戶推送合適的音樂。
音頻合成
基于服裝風格遷移實現(xiàn)場景感知下的人物視頻生成
《Towards Using Clothes Style Transfer for Scenario-aware Person Video Generation》
該方向致力于解決視頻中人物個性化穿搭和背景場景自由的選擇問題。創(chuàng)新上,設(shè)計了多個解耦 encoder 學習人物不同的屬性(身份,衣服和姿態(tài)),通過共享 decoder 融合多層面信息。
不同于圖片任務(wù),視頻需要學習幀之間的變化,所以設(shè)計了幀間判別器(Inner-frame Discriminator)大幅度提升了穩(wěn)定性。具體來說,在模型生成的結(jié)果上應用掩碼(mask),人物可切換到任意場景上。工作在公開數(shù)據(jù)集 TEDXPeople,相對 baseline 系統(tǒng)(CVPR2021)視頻中衣服個性化的多項客觀指標均有顯著改善,可以達到 SOTA 效果:SSIM +0.047, PSNR +4.6, FID(越小越好) -0.4, FVD(越小越好) -0.543。
場景感知的服裝風格遷移模型框架
在數(shù)字人多模態(tài)生成的場景和業(yè)務(wù)中,數(shù)字人主播衣服的個性化穿搭和場景自由的選擇,為用戶提供了自主可控的個性化能力,可大幅增加數(shù)字人生態(tài)的多樣性。
音頻理解
基于細粒度語境知識選擇的端到端(語境)語音識別提升方法
《IMPROVING END-TO-END CONTEXTUAL SPEECH RECOGNITION WITH FINE-GRAINED CONTEXTUAL KNOWLEDGE SELECTION》
該工作在一種被稱為協(xié)同解碼(Collaborative Decoding, ColDec)的語音識別定制化 / 個性化方法的基礎(chǔ)上,提出了細粒度語境知識選擇機制(Fine-grained Contextual Knowledge Selection),來進一步增強該方法在大熱詞列表和較多干擾熱詞情境下的語音識別定制化性能。在先前工作中,一種被稱為協(xié)同解碼(Collaborative Decoding)的語音識別定制化技術(shù)有效地提升了定制化識別性能。
本文針對其在大熱詞列表和較多干擾熱詞情境下的性能衰減問題,提出了細粒度語境知識選擇機制,進一步增強了協(xié)同解碼技術(shù)在定制化場景下的能力。在公開數(shù)據(jù)集 Librispeech 上,本文方法在基礎(chǔ) CIF 語音識別模型的 test-clean 2.12% 的 WER 基礎(chǔ)上,進一步為 WER 帶來了約 5% 的相對下降;在內(nèi)部 16w 小時工業(yè)級 ASR 數(shù)據(jù)集訓練的語音識別模型的基礎(chǔ)上,本文方法在真實會議測試集上為 CER 帶來了最高約 16% 的相對下降。
應用場景方面,該方法可被用于語音識別定制化,例如在智能語音助手和在線視頻會議等應用場景中,許多同背景相關(guān)的關(guān)鍵短語、個性化信息、熱詞等內(nèi)容都較難識別。此外在移動端智能語音助手的應用場景下,聯(lián)系人列表中的聯(lián)系人姓名,頻繁出沒的地點位置等個性化信息;在線會議場景下,參會人員的姓名,會議主題相關(guān)的專業(yè)術(shù)語等,針對性地提升這些定制化和個性化文本內(nèi)容的語音識別性能,在實際應用場景中有重要意義。
非自回歸 Transformer 自動語音識別的最小詞誤差訓練
《MINIMUM WORD ERROR TRAINING FOR NON-AUTOREGRESSIVE TRANSFORMER-BASED CODE-SWITCHING ASR》
這篇論文由字節(jié)跳動和南洋理工大學(NTU)共同完成。近年來由于基于非自回歸 Transformer(NAT)的自動語音識別(ASR)框架的以下優(yōu)點,分別是 “當前的輸出與歷史的輸出無關(guān)” 以及“其推理速度非常快”,其在業(yè)界日益受到重視。
對此,團隊對于其在語碼轉(zhuǎn)換語音識別任務(wù)(CSSR)上的性能有所期待。另外據(jù)不完全了解,似乎并沒有出現(xiàn)將最小詞錯率(MWER)準則應用于 NAT 模型的先例,所以該工作在一定程度上填補了此項空白,且在 SEAME 語碼轉(zhuǎn)換數(shù)據(jù)集上得到了驗證。
本文的貢獻主要在以下兩個方面:1、我們在語碼轉(zhuǎn)換的場景下,提出了多種 CTC 掩蔽的方式訓練 NAT 模型;2、我們在 MWER 訓練準則下,提出了多種 N-best 假設(shè)的生成方法。
發(fā)現(xiàn)及結(jié)論分別是:1、無論在單語言還是跨語言的場景下,上下文相關(guān)的場景信息非常重要,而 NAT 沒有歷史信息,NAT 模型相比自回歸的 Transformer(AT)得到了一致性更差的結(jié)果;2、嚴重受限于 N-best 假設(shè)的生成方法,在 NAT 模型上進行基于 N-best 的 MWER 訓練只得到了細微的提升,所以如何生成更豐富的 N-best 有待進一步研究。
使用梯度掩碼改進端到端語音識別的偽標簽訓練
《IMPROVING PSEUDO-LABEL TRAINING FOR END-TO-END SPEECH RECOGNITION USING GRADIENT MASK》
一直以來,打偽標簽在自監(jiān)督學習中都是最重要的方法,最近在語音識別領(lǐng)域也展現(xiàn)出極好的效果,但是自監(jiān)督學習對偽標簽的質(zhì)量極其敏感,主要是因為偽標簽中的錯誤或者噪聲常常會導致模型訓練的不穩(wěn)定并最終收斂到非最佳的狀態(tài),特別是對于 e2e 的模型比如 RNNT。
對此,該論文提出了 Gradient-mask 的方法來應對以上問題。此方法在訓練過程中抹去了 encoder 中可見 input 的對應梯度,從而鼓勵模型從不可見的部分進行推測,并且能有效降低模型對 corrupted label 的 overfit。
應用場景方面,此方法可以有效應對模型 overfit 到 corrupted label 并提升模型訓練的效果,例如半監(jiān)督自學習中,因為 domain 不 match 等原因?qū)е?pseudo-label 質(zhì)量過差,以及已知一部分數(shù)據(jù)標注質(zhì)量過差的問題。
ICASSP 2022 多方會議轉(zhuǎn)錄挑戰(zhàn)賽的火山語音系統(tǒng)
《THE VOLCSPEECH SYSTEM FOR THE ICASSP 2022 MULTI-CHANNEL MULTI-PARTY MEETING TRANSCRIPTION CHALLENGE》
會議場景是語音識別和說話人日志技術(shù)應用中最有價值和挑戰(zhàn)的場景之一,會議場景包含了豐富的說話風格和復雜的聲學條件,需要考慮重疊語音、未知數(shù)量說話人、遠場信號、噪音、混響等挑戰(zhàn)。
ICASSP 2022 多通道多方會議轉(zhuǎn)錄挑戰(zhàn)(M2MeT),提供了 120 小時真實記錄的中文會議數(shù)據(jù),包含 8 通道麥克風遠場數(shù)據(jù)和對應耳機麥克風采集的近場數(shù)據(jù)。M2MeT 挑戰(zhàn)賽包括多說話人語音識別和說話人日志兩個賽道,團隊在限定訓練數(shù)據(jù)子賽道上分別獲得第二名和第四名。
針對多說話人語音識別賽道,團隊提出一種神經(jīng)網(wǎng)絡(luò)前端模塊和語音識別模塊端到端聯(lián)合訓練的方法,輸入 8 通道音頻輸出多說話人識別文本,除此之外加入了豐富的 8 通道數(shù)據(jù)仿真,在測試集上和官方基線相比 CER 相對下降 32.6%。
在說話人日志賽道中,結(jié)合前端信號處理技術(shù),團隊提出一種融合聲源定位信息的說話人日志方法,提高識別準確率;同時針對競賽數(shù)據(jù)中存在的說話人重疊問題,提出一種多通道融合算法,減少重疊部分的說話人漏檢,最后采用修改的 DOVER-Lap 算法對多套系統(tǒng)進行融合,最終在測試集上的 DER(說話人日志錯誤率)相比官方基線相對下降 53.7%。該技術(shù)可以被用在會議室多通道麥克風場景下,生成包含說話人信息的多說話人語音轉(zhuǎn)錄結(jié)果。
超腦方向
基于稀疏共享子網(wǎng)絡(luò)的跨語言語音表征學習
《LANGUAGE ADAPTIVE CROSS-LINGUAL SPEECH REPRESENTATION LEARNING WITH SPARSE SHARING SUB-NETWORKS》
該工作提出了一種基于稀疏共享結(jié)構(gòu)的多語言語音表征學習方法,即從模型中劃分出多個稀疏子網(wǎng)絡(luò)來分別對不同語言進行建模,進而實現(xiàn)語言自適應訓練,每個語言的子網(wǎng)絡(luò)都通過裁剪不重要的參數(shù)進行提取。
基于此,文中探索了一種基于彩票假設(shè) (Lottery Ticket Hypothesis) 的提取方法以及另一種基于一階泰勒展開的快速提取方法。在下游多語言語音識別任務(wù)上,所提出的方法可以大幅降低基線 XLSR 模型的錯誤率,并超過 Gating Network、Adapter 等其他自適應訓練方法。
基于稀疏共享結(jié)構(gòu)的多語言預訓練流程
在國際化背景下,為了滿足不同語言的字幕、審核和翻譯等需求,需要針對各個語言去搭建語音識別系統(tǒng)。多語言語音識別的目標是用單一模型去支持多個語言的語音識別,可以有效的減輕部署和維護的成本,并能在一些低資源場景下提升識別效果,具有非常重要的意義。
關(guān)于字節(jié)跳動火山語音團隊
字節(jié)跳動火山語音團隊,原字節(jié)跳動 AI Lab Speech & Audio 智能語音與音頻團隊,致力于為公司各個業(yè)務(wù)提供音頻理解、音頻合成、對話交互、音樂檢索和智能教學等多種 AI 能力與方案。自 2017 年成立以來,團隊專注研發(fā)行業(yè)領(lǐng)先的 AI 智能語音技術(shù),為今日頭條、抖音、剪映、西瓜視頻、番茄小說、飛書辦公套件等字節(jié)跳動旗下的重量級產(chǎn)品提供了各類 AI 解決方案,不斷探索 AI 與業(yè)務(wù)場景的高效結(jié)合,以實現(xiàn)更大的用戶價值,截至目前團隊已服務(wù)上百個業(yè)務(wù)合作伙伴。伴隨字節(jié)跳動業(yè)務(wù)的快速發(fā)展,團隊的語音識別和語音合成覆蓋了多種語言和方言,已有多篇論文入選各類 AI 頂級會議,未來希望繼續(xù)發(fā)展 70 + 語言和 20 + 方言,用于滿足內(nèi)容創(chuàng)作與交流平臺的需求。
















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號